
I mentioned in the conclusions of Opentext 101: The buffer is going to explode! that there were some documents pending to be copied from the buffer to the repository. I spent couple of hours trying to solve the issue which was great to know a little bit more about Archive Server and its architecture. There is some information that is not explained in the product documents which is quite useful, we only need a SQL trace and some patience
A travel to Opentext Archive Server insides!
During my test I wanted to get the document ID of this documents having only the folders where they are stock. Archive Server works in a certain way when it archives a document from SAP system:
- The document file will be handle from the SAP System (or any other application) to Archive Server using the web services on the Archive Server Tomcat. During this part the Archive Server will generate a document ID that it will use during the whole process.
- Archive Server will copy the document file to the storage in the server. This storage can be a local storage, NAS, etc.
- Archive Server will copy the document file data to the database using the ATTRIB.ATR file and the document ID. This data contains information about the type of document, location of the document, creation date, etc.
The following image shows how SAP system and Archive Server works when accessing a document:
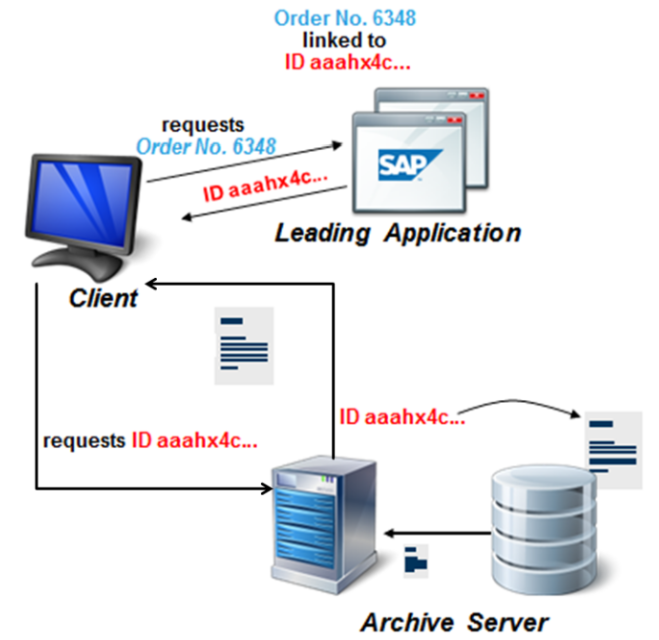
Knowing this it should be possible to have a document ID knowing the location of a file in a certain volume, right? My idea was to execute the dinfo and volck commands in order to fix the document in the buffer. Since I didn’t know the specific tables that contains the document data in the database I set a trace in the SQL Server database using SQL Server Profile. Next step was to execute the dinfo command on a random document:
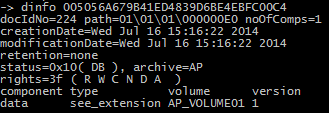
The SQL Server Profiler trace showed the following information:
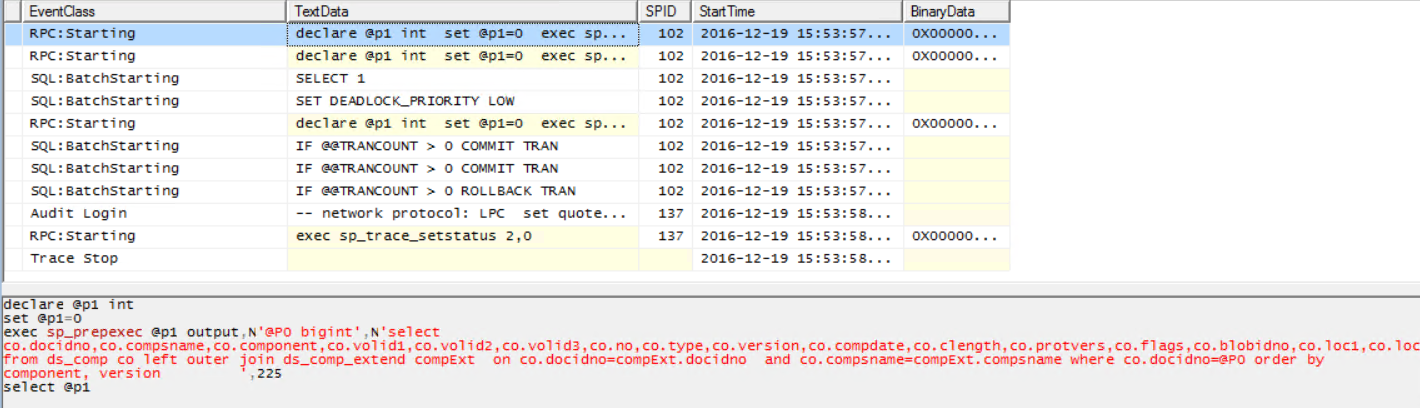
So I decided to execute all the queries at the same time in the SQL Server Management Studio and I got the following information:
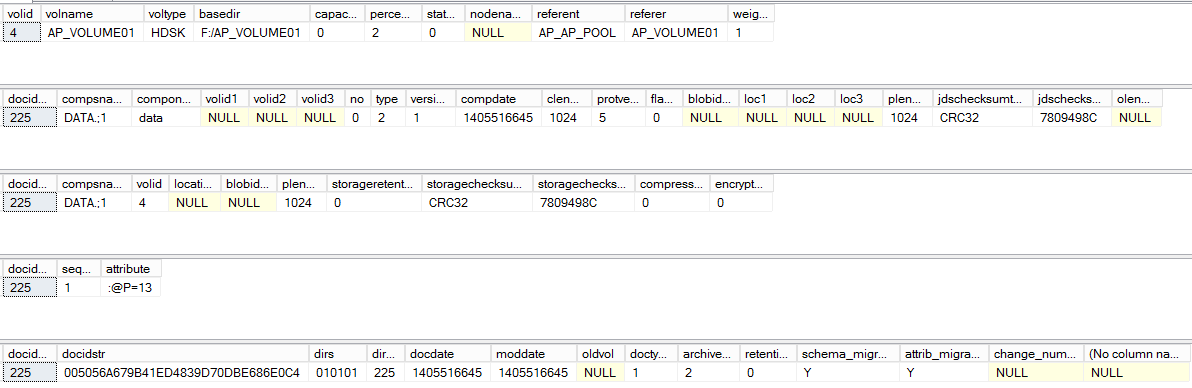
ds_what??
From the queries and the screenshot we can get the following information about the tables Archive Server uses:
- ds_volid: Information about the volumes defined.
- ds_pool: Information about the pool defined.
- ds_comp: Information about documents such as folder name, file name, creation date, size, etc.
- ds_comp_location: Information about documents such as folder name, volume where it is located, size, etc.
- ds_seqattrib: Relation between a document and its type.
- ds_doc: Information about documents such as folder name, document id, location, creation date, modification date, archive that contains it, etc.
- ds_deleted: Information about deleted documents.
I’m not going to fully explain the tables but I think you see the point, right?
Give me some examples, I need real life stuff!
Lets say we want to know the document ID of a document located on the folder 000A4A05. We don’t even know which volume contains it, the type of the volume or any other information. First thing we have to do is convert 000A4A05 to decimal since the folder name is a hexadecimal number:

You can have it in binary or octal too but it is not really useful… From now the docidno field will be equal to 674309 since the document folder name is kept as a decimal number inside the database. Next step is to execute the following query to get some information about the document:
|
1 2 3 |
select co.docidno,co.compsname,co.component,co.volid1,co.volid2,co.volid3,co.no,co.type,co.version,co.compdate,co.clength,co.protvers,co.flags,co.blobidno,co.loc1,co.loc2,co.loc3,co.plength,co.jdschecksumtype,co.jdschecksum,compExt.olength from ds_comp co left outer join ds_comp_extend compExt on co.docidno=compExt.docidno and co.compsname=compExt.compsname where co.docidno='674309' order by component, version |
You can see the results in the following screenshot. The important field here is compsname which we can use in the next queries:

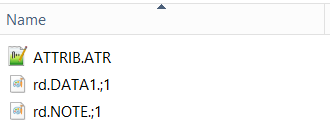
If we check the document folder we see two files name rd.DATA1.;1 and rd.NOTE.;1 as stated in the ds_comp table:
If we want to get the document ID we only need to execute the following query in the database:
|
1 2 3 |
SELECT docidno,docidstr,dirs,dirno,docdate,moddate,oldvol,doctype,archiveno,retention,schema_migrated,attrib_migrated,change_number FROM ds_doc WHERE docidno='674309' |
The document ID shows in the results:

Now we can execute the dinfo on the dsClient to get the full information of the document:
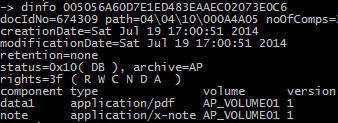
We can use the document ID to execute the volck -p utility, open the document from SAP using OAAD transaction, etc.
Conclusions
We can learn some interesting stuff using just a SQL trace and some time. We usually choose the easiest way meaning we try to find the solution for an issue on Google… Which in my opinion is a completely wrong way to solve a problem. Next time try to spend some time investigating the issue and the application you are working with, I promise it won’t be wasted time!
One thought to “Opentext 101: Journey to the Centre of Archive Server”