
I worked lately with SAP HANA Vora and Cloudera and I am really impressed with both applications. Right now it is easier to deploy a configure Apache Hadoop using Cloudera Manager and Cloudera CDH, you don’t have to install and configure each part of Apache Hadoop individually. SAP takes advantage of Apache Hadoop and release SAP HANA Vora. Vora is an in-memory computing engine designed to make Hadoop more usable. You can read more about it here and register for a free trial.
The biggest problem I found when installing HANA Vora is the documentation. Don’t get me wrong, there is a lot of documentation about Cloudera and some about SAP HANA Vora. The main problem is that this documents are not related to each other. The HANA Vora guide changed a lot from version 1.1 or 1.2, I did an installation using version 1.2 and it was hell. The version 1.3 and 1.4 have a lot for new information but there are some parts that are not so clear. I decided to start this articles series about SAP HANA Vora that you can use if you want to install and use it.
SAP HANA Vora Architecture
The architecture of HANA Vora is described in the guide:
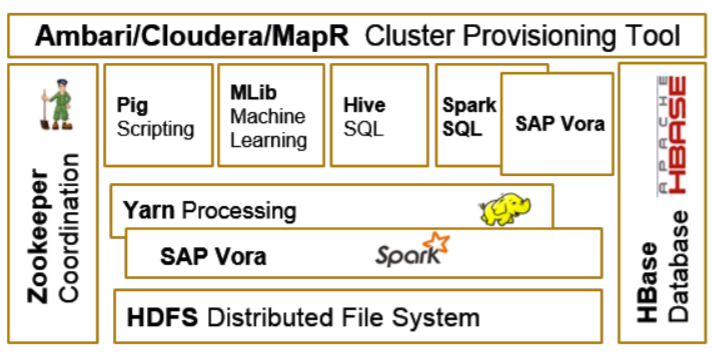
As you can see the architecture is almost the same one as Apache Hadoop, we can see the important services as HDFS, HBase, Yarn, Spark, etc. Everything should be running on a provisioning tool as Ambari, Cloudera or MapR so you are free to use the one you prefer. On a closer look on the Vora Engine we can see that each Data Node has at least the Vora In-memory Engine and the Spark Worker and the Hadoop HDFS for file sharing between the Data Nodes. Each Data Node has to be running on individual hosts:
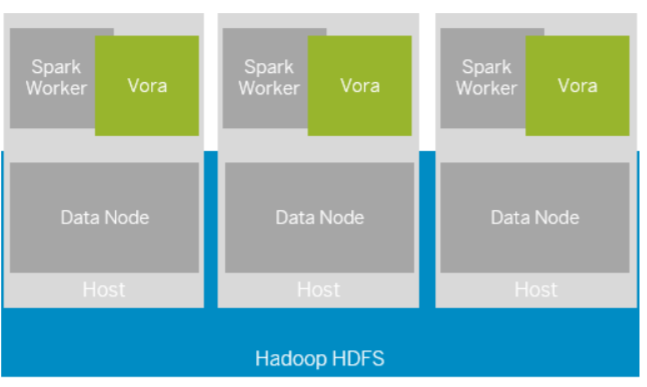
Considering this we will need at least the following setup for installing SAP HANA Vora:
- At least 1 host for the Cluster Provisioning Tool that will be the manager.
- At least 2-N host for the Data Nodes.
Required hardware
Next step is to go shopping for new servers. Hadoop and SAP HANA Vora needs tons of resources and they are not cheap applications considering the required hardware. The recommended hardware for a DataNode/Task Tracker is the following one:
- 12 to 24 HD of 1 to 4 TB.
- 2 quad-/hex-/octo-core CPUs running at 2,0GHz to 2,5GHz.
- 64 to 128GB of RAM.
- 10GB Ethernet depending on the storage you managed.
Really cheap, right? You can read a little bit more about the requirements here. The required hardware has to be calculated depending on the workload of your system, there is no universal guide that will work in every case. In our case we used the following servers for a small demo system:
- Manager Node:
- 1TB HD.
- 4 quad-core CPUs running 2,5GHz (in the beginning we had only 2 but the CPU load was always at 100%).
- 64GB RAM.
- 10GB Ethernet depending on the storage you managed.
- 2 x Data Nodes/Task Trackers (they work on both ways):
- 1TB HD.
- 2 quad-core CPUs running 2,5GHz (in the beginning we had only 2 but the CPU load was always at 100%).
- 24GB RAM.
- 10GB Ethernet depending on the storage you managed.
We’ll check the load of all the servers after some weeks of use and evaluate if it is necessary to raise the resources on any server.
Cluster Provisioning Tool
Next step is to decide which Cluster Provisioning Tool you want to use for the Manager Node and the Nodes. In this case you have 3 different flavours:
You can choose the one you prefer but keep in mind that SAP HANA Vora is not compatible with all their versions. You can check SAP Note 2213226 – Prerequisites for installing SAP Vora: Operating Systems and Hadoop Components to see what are the combinations of OS version and Cluster Provisioning Tools:

Also keep in mind the Java Version and the Spark version when installing the software since SAP HANA Vora is not compatible with all the available versions:

In my case I decided to use Cloudera Manager since I think it is easy to use. One thing you have to keep in mind about Cloudera Manager is not to do the installation using the VM image you can download. You should the Cloudera Manager installer since the VM image has a lot of already configured stuff on both Cloudera and the operating system. I tried to do the installation using the VM image and it was a completely disaster. I’m going to say it one more time:
DO NOT USE THE VM IMAGE FOR INSTALLING CLOUDERA MANAGER
I think it is pretty clear…
Next steps
On the following articles I will explain a bit about:
- How to install Cloudera Manager using the correct versions.
- Deploy the CDH on the Nodes.
- Create the required roles on Cloudera for Spark, Yarn, HDB, HBase with their configuration.
- Install and deploy SAP HANA Vora.
- Connect SAP HANA Vora to HANA databases.
- Use SAP HANA Vora.
I think there is a lot of work to do in the next months so we’ll go step by step. See you after holidays!